
知识点:
- mysql同步的基本原理
- 双向同步的时候,mysql怎么保证不会陷入死循环
答:每个mysql实例都要配置一个server_id,来保证数据最早是从哪个实例写入,从而避免陷入死循环。
一、双主【开启log_slave_updates】
比如说,最简单的双主同步A<->B。

当数据从A写入一条记录recordA,会绑定A的server_id,比如1;
同步到B,B发现这条记录不是自己的,写入库中,并开启log_slave_updates,写入binlog中,并记录这条对应的server_id=1,还是A写的(不抢功劳)。
由于双向同步,这条数据又传回A,此时A发现这条记录的生产者是自己(比对server_id一致),就丢弃掉,避免了死循环。
二、环形同步【开启log_slave_updates】

环形同步需要开启log_slave_updates,才能同步到对应的下一级。 为什么开启了写日志还不会出现死循环呢?原理跟上面类似,数据写入A,传到B写入,传到C写入,回传到A,发现是自己的,停止该条同步,结束。
三、多源双主同步【多源从机开启log_slave_updates,其余关闭!!!】
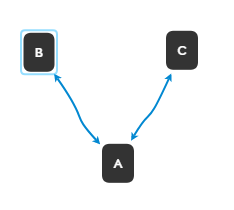
最近遇到升级版的,双主还多源同步(5.7版本支持多源),此时只有做为多源同步的从机A才能开启log_slave_updates,B和C关闭。
假设:ABC都开启log_slave_updates,当数据写入B,此时数据流向存在以下几种情况:
1.B -> A -> B (理想中结束)
2.B -> A -> C -> A -> B (勉强结束,但A执行了两次)
3.B -> A -> C -> A -> C -> A -> C ... (死循环)
看官建议自行搭建测试,看是否写入条数据,一直陷入死循环~~
Comments