
当对表进行DDL的同时,如果产生的DML记录超过表的总行数10%,就会清空表的统计信息,直到DDL结束才重新统计
一、问题现象
线上有个数据库CPU飙升到100%,出现大量select慢SQL,首先使用了SQL限流工具,限流了大部分同类型SQL,CPU降至50%。
经过了解,凌晨的时候对某个大表A(9亿条)进行添加字段,DDL的同时又对该表进行归档delete操作。Alter和Delete两个SQL一直执行到早上8点多才被手动kill掉!
二、问题处理
- 捞出高频且执行较慢的SQL,进行explain,发现有显示正确的索引;
- 查看A表的总行数,
show index from A,发现所有Cardinality值都为0! - 执行
analyze table A重新统计表信息; - 停止SQL限流,CPU和慢SQL降下来,恢复正常。
三、问题排查
首先应该知道对表进行DDL的同时,如果该表有产生DML语句,此时数据是会存在innodb_online_alter_log中,如果执行过久,且产生了大量DML,可能会报1799Creating index '%s' required more than 'innodb_online_alter_log_max_size' bytes of modification log. Please try again.;
从阿里提供的bug链接(附1),了解到当对表进行DDL的同时,如果产生的DML记录超过表的总行数10%,那就会清空表的统计信息,直到DDL结束才会重新统计!
源码分析:
备注:函数挑转会在注释中加入<=====,以便看清流向
storage\innobase\row\row0mysql.cc
Does an update or delete of a row for MySQL.
@return error code or DB_SUCCESS */
UNIV_INTERN
dberr_t
row_update_for_mysql(
/*=================*/
byte* mysql_rec, /*!< in: the row to be updated, in
the MySQL format */
row_prebuilt_t* prebuilt) /*!< in: prebuilt struct in MySQL
handle */
{
/*
……
一些表正常判断、加锁、删改记录,重点在这个函数的最后面
……
*/
/* We update table statistics only if it is a DELETE or UPDATE
that changes indexed columns, UPDATEs that change only non-indexed
columns would not affect statistics.
修改表的统计信息statistics,只会在DELETE或者UPDATE有更改到索引列,
如果只更新到非索引列,那就不会影响统计信息。
delete肯定会影响到所有列,所以直接进入row_update_statistics_if_needed函数
*/
if (node->is_delete || !(node->cmpl_info & UPD_NODE_NO_ORD_CHANGE)) {
row_update_statistics_if_needed(prebuilt->table); // <=====
}
trx->op_info = "";
return(err);
}/*********************************************************************//**
Updates the table modification counter and calculates new estimates
for table and index statistics if necessary. */
UNIV_INLINE
void
row_update_statistics_if_needed(
/*============================*/
dict_table_t* table) /*!< in: table */
{
ib_uint64_t counter;
ib_uint64_t n_rows;
if (!table->stat_initialized) {
DBUG_EXECUTE_IF(
"test_upd_stats_if_needed_not_inited",
fprintf(stderr, "test_upd_stats_if_needed_not_inited "
"was executed\n");
);
return;
}
// stat_modified_counter记录该表修改的行数
counter = table->stat_modified_counter++;
// 获取表的总行数,应该是从information_schmea.tables获取
n_rows = dict_table_get_n_rows(table);
// 判断表是否启用持久统计信息,默认值都是true;
// 如果修改表的行数超过10%,并且启用自动重新计算统计信息(默认true),
// 那就会把表放进recalc_pool并置stat_modified_counter为0
if (dict_stats_is_persistent_enabled(table)) {
if (counter > n_rows / 10 /* 10% */
&& dict_stats_auto_recalc_is_enabled(table)) {
dict_stats_recalc_pool_add(table); // <=====
table->stat_modified_counter = 0;
}
return;
}
/* Calculate new statistics if 1 / 16 of table has been modified
since the last time a statistics batch was run.
We calculate statistics at most every 16th round, since we may have
a counter table which is very small and updated very often.
如果修改的行数counter小于10%,但大于16%(加了个16,估计是避免表初始化的时候频繁更新统计值),
那就直接触发更新统计值,进入dict_stats_update
*/
if (counter > 16 + n_rows / 16 /* 6.25% */) {
ut_ad(!mutex_own(&dict_sys->mutex));
/* this will reset table->stat_modified_counter to 0 */
dict_stats_update(table, DICT_STATS_RECALC_TRANSIENT);
}
}storage\innobase\dict\dict0stats_bg.cc
/*
把表的id推到recalc_pool(队列)中
*/
UNIV_INTERN
void
dict_stats_recalc_pool_add(
/*=======================*/
const dict_table_t* table) /*!< in: table to add */
{
ut_ad(!srv_read_only_mode);
mutex_enter(&recalc_pool_mutex);
/* quit if already in the list */
for (recalc_pool_iterator_t iter = recalc_pool.begin();
iter != recalc_pool.end();
++iter) {
if (*iter == table->id) {
mutex_exit(&recalc_pool_mutex);
return;
}
}
recalc_pool.push_back(table->id); // <===== 推到队列recalc_pool中,后面直接跳转到线程处理中DECLARE_THREAD
mutex_exit(&recalc_pool_mutex);
os_event_set(dict_stats_event);
}/*****************************************************************//**
后台线程,不断去拉取recalc_pool的第一个值,然后进行计算
This is the thread for background stats gathering. It pops tables, from
the auto recalc list and proceeds them, eventually recalculating their
statistics.
@return this function does not return, it calls os_thread_exit() */
extern "C" UNIV_INTERN
os_thread_ret_t
DECLARE_THREAD(dict_stats_thread)(
/*==============================*/
void* arg MY_ATTRIBUTE((unused))) /*!< in: a dummy parameter
required by os_thread_create */
{
my_thread_init();
ut_a(!srv_read_only_mode);
srv_dict_stats_thread_active = TRUE;
while (!SHUTTING_DOWN()) {
/* Wake up periodically even if not signaled. This is
because we may lose an event - if the below call to
dict_stats_process_entry_from_recalc_pool() puts the entry back
in the list, the os_event_set() will be lost by the subsequent
os_event_reset(). */
os_event_wait_time(
dict_stats_event, MIN_RECALC_INTERVAL * 1000000);
if (SHUTTING_DOWN()) {
break;
}
dict_stats_process_entry_from_recalc_pool(); // <=====
os_event_reset(dict_stats_event);
}
srv_dict_stats_thread_active = FALSE;
my_thread_end();
/* We count the number of threads in os_thread_exit(). A created
thread should always use that to exit instead of return(). */
os_thread_exit(NULL);
OS_THREAD_DUMMY_RETURN;
}/*****************************************************************//**
Get the first table that has been added for auto recalc and eventually
update its stats. */
static
void
dict_stats_process_entry_from_recalc_pool()
/*=======================================*/
{
table_id_t table_id;
ut_ad(!srv_read_only_mode);
/*
pop the first table from the auto recalc pool
pop池中的第一个table,指向table_id中
*/
if (!dict_stats_recalc_pool_get(&table_id)) {
/* no tables for auto recalc */
return;
}
dict_table_t* table;
mutex_enter(&dict_sys->mutex);
table = dict_table_open_on_id(table_id, TRUE, DICT_TABLE_OP_NORMAL);
if (table == NULL) {
/* table does not exist, must have been DROPped
after its id was enqueued */
mutex_exit(&dict_sys->mutex);
return;
}
/* Check whether table is corrupted */
if (table->corrupted) {
dict_table_close(table, TRUE, FALSE);
mutex_exit(&dict_sys->mutex);
return;
}
table->stats_bg_flag = BG_STAT_IN_PROGRESS;
mutex_exit(&dict_sys->mutex);
/* ut_time() could be expensive, the current function
is called once every time a table has been changed more than 10% and
on a system with lots of small tables, this could become hot. If we
find out that this is a problem, then the check below could eventually
be replaced with something else, though a time interval is the natural
approach.
判断两次统计时间间隔,如果低于10s,那就重新放回pool中,等待下一次统计;
否则真正进入dict_stats_update修改统计值
*/
if (ut_difftime(ut_time(), table->stats_last_recalc)
< MIN_RECALC_INTERVAL) {
/* Stats were (re)calculated not long ago. To avoid
too frequent stats updates we put back the table on
the auto recalc list and do nothing. */
dict_stats_recalc_pool_add(table);
} else {
dict_stats_update(table, DICT_STATS_RECALC_PERSISTENT); // <=====
}
mutex_enter(&dict_sys->mutex);
table->stats_bg_flag = BG_STAT_NONE;
dict_table_close(table, TRUE, FALSE);
mutex_exit(&dict_sys->mutex);
}storage\innobase\dict\dict0stats.cc
/*********************************************************************//**
Calculates new estimates for table and index statistics. The statistics
are used in query optimization.
@return DB_SUCCESS or error code */
UNIV_INTERN
dberr_t
dict_stats_update(
/*==============*/
dict_table_t* table, /*!< in/out: table */
dict_stats_upd_option_t stats_upd_option)
/*!< in: whether to (re) calc
the stats or to fetch them from
the persistent statistics
storage */
{
char buf[MAX_FULL_NAME_LEN];
ut_ad(!mutex_own(&dict_sys->mutex));
/***
* 省略一些判断,后面只截取DICT_STATS_RECALC_PERSISTENT的处理
***/
switch (stats_upd_option) {
case DICT_STATS_RECALC_PERSISTENT:
if (srv_read_only_mode) {
goto transient;
}
/* Persistent recalculation requested, called from
1) ANALYZE TABLE, or
2) the auto recalculation background thread, or
3) open table if stats do not exist on disk and auto recalc
is enabled
重点:请求重新计算统计值,只有当手动执行ANALYZE TABLE或者进入到自动重新计算后台线程,
或者打开的表的stats不存在
*/
/* InnoDB internal tables (e.g. SYS_TABLES) cannot have
persistent stats enabled */
ut_a(strchr(table->name, '/') != NULL);
/* check if the persistent statistics storage exists
before calling the potentially slow function
dict_stats_update_persistent(); that is a
prerequisite for dict_stats_save() succeeding */
if (dict_stats_persistent_storage_check(false)) {
dberr_t err;
err = dict_stats_update_persistent(table); // <=====
if (err != DB_SUCCESS) {
return(err);
}
err = dict_stats_save(table, NULL);
return(err);
}
/* Fall back to transient stats since the persistent
storage is not present or is corrupted */
ut_print_timestamp(stderr);
fprintf(stderr,
" InnoDB: Recalculation of persistent statistics "
"requested for table %s but the required persistent "
"statistics storage is not present or is corrupted. "
"Using transient stats instead.\n",
ut_format_name(table->name, TRUE, buf, sizeof(buf)));
goto transient;
/***
*
* 其它case,省略
*
***/
}
transient:
dict_table_stats_lock(table, RW_X_LATCH);
dict_stats_update_transient(table);
dict_table_stats_unlock(table, RW_X_LATCH);
return(DB_SUCCESS);
}/*********************************************************************//**
Calculates new estimates for table and index statistics. This function
is relatively slow and is used to calculate persistent statistics that
will be saved on disk.
@return DB_SUCCESS or error code */
static
dberr_t
dict_stats_update_persistent(
/*=========================*/
dict_table_t* table) /*!< in/out: table */
{
dict_index_t* index;
DEBUG_PRINTF("%s(table=%s)\n", __func__, table->name);
// 加排它锁
dict_table_stats_lock(table, RW_X_LATCH);
/* analyze the clustered index first */
index = dict_table_get_first_index(table);
if (index == NULL
|| dict_index_is_corrupted(index)
|| (index->type | DICT_UNIQUE) != (DICT_CLUSTERED | DICT_UNIQUE)) {
/* Table definition is corrupt */
dict_table_stats_unlock(table, RW_X_LATCH);
dict_stats_empty_table(table);
return(DB_CORRUPTION);
}
ut_ad(!dict_index_is_univ(index));
// 分析索引
dict_stats_analyze_index(index); // <=====
ulint n_unique = dict_index_get_n_unique(index);
table->stat_n_rows = index->stat_n_diff_key_vals[n_unique - 1];
table->stat_clustered_index_size = index->stat_index_size;
/* analyze other indexes from the table, if any */
table->stat_sum_of_other_index_sizes = 0;
for (index = dict_table_get_next_index(index);
index != NULL;
index = dict_table_get_next_index(index)) {
ut_ad(!dict_index_is_univ(index));
if (index->type & DICT_FTS) {
continue;
}
dict_stats_empty_index(index);
if (dict_stats_should_ignore_index(index)) {
continue;
}
if (!(table->stats_bg_flag & BG_STAT_SHOULD_QUIT)) {
dict_stats_analyze_index(index);
}
table->stat_sum_of_other_index_sizes
+= index->stat_index_size;
}
table->stats_last_recalc = ut_time();
table->stat_modified_counter = 0;
table->stat_initialized = TRUE;
dict_stats_assert_initialized(table);
dict_table_stats_unlock(table, RW_X_LATCH);
return(DB_SUCCESS);
}/*********************************************************************//**
Calculates new statistics for a given index and saves them to the index
members stat_n_diff_key_vals[], stat_n_sample_sizes[], stat_index_size and
stat_n_leaf_pages. This function could be slow. */
static
void
dict_stats_analyze_index(
/*=====================*/
dict_index_t* index) /*!< in/out: index to analyze */
{
ulint root_level;
ulint level;
bool level_is_analyzed;
ulint n_uniq;
ulint n_prefix;
ib_uint64_t total_recs;
ib_uint64_t total_pages;
mtr_t mtr;
ulint size;
DBUG_ENTER("dict_stats_analyze_index");
DBUG_PRINT("info", ("index: %s, online status: %d", index->name,
dict_index_get_online_status(index)));
DEBUG_PRINTF(" %s(index=%s)\n", __func__, index->name);
// 清空所有索引统计值
dict_stats_empty_index(index);
mtr_start(&mtr);
mtr_s_lock(dict_index_get_lock(index), &mtr);
// 重点:获取表B-tree的pages,由于该表此时正DDL,所以返回了ULINT_UNDEFINED
size = btr_get_size(index, BTR_TOTAL_SIZE, &mtr);
if (size != ULINT_UNDEFINED) {
index->stat_index_size = size;
size = btr_get_size(index, BTR_N_LEAF_PAGES, &mtr);
}
/* Release the X locks on the root page taken by btr_get_size() */
mtr_commit(&mtr);
switch (size) {
case ULINT_UNDEFINED:
dict_stats_assert_initialized_index(index); // <=====
DBUG_VOID_RETURN; // <===== 重点:直接跳出,没有统计信息,等待DDL结束才统计,导致此时Cardinality一直为0,结束
case 0:
/* The root node of the tree is a leaf */
size = 1;
}
/***
*
* 后面还有一大段用于处理统计信息,但跟我们没啥关系了
*
***/
}四、复现
- 使用DMS构建大表测试数据(200w)
CREATE TABLE `t_user_recommend_history` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键', `user_id` varchar(20) NOT NULL COMMENT '用户主键', `content_type` tinyint(4) NOT NULL COMMENT '内容类型', `content_id` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '内容主键', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL COMMENT '修改时间', `is_flag` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否有效', PRIMARY KEY (`id`), KEY `idx_1` (`user_id`,`is_flag`,`content_id`), KEY `idx_2` (`create_time`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
- 会话a,添加字段
ALTER TABLE `t_user_recommend_history` ADD COLUMN `delivery_area` tinyint(4) NOT NULL DEFAULT 0; - 会话b,删除数据
delete t1 from t_user_recommend_history where id<=200000 - 会话c观察show index
show index from t_user_recommend_history
delete一段时间后
- 执行查询,全表扫描
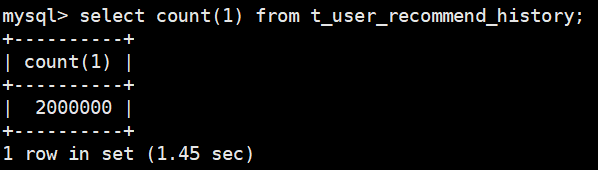

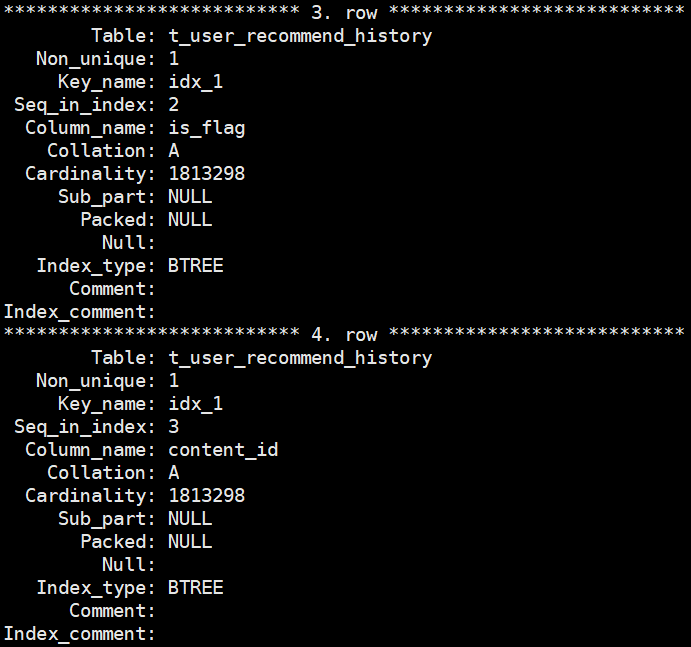
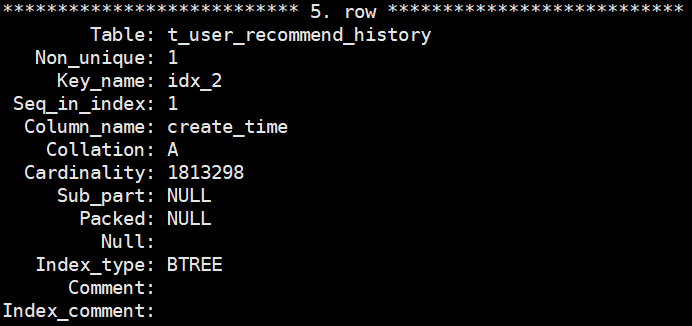
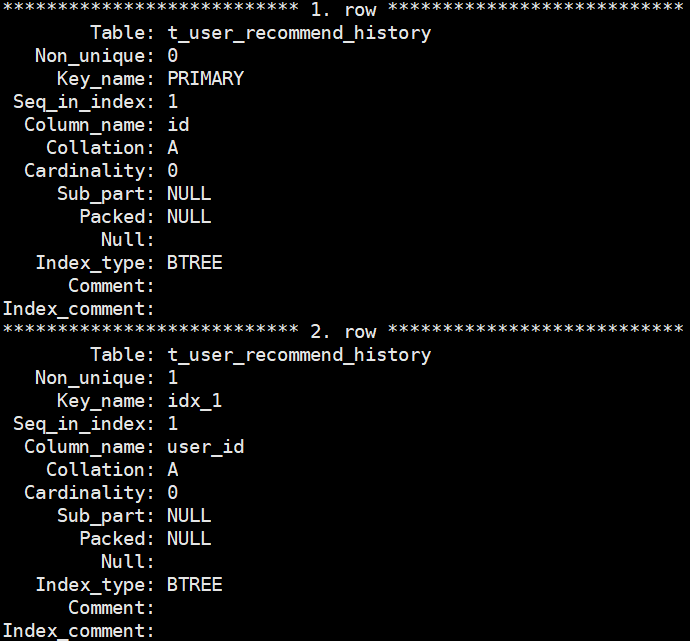
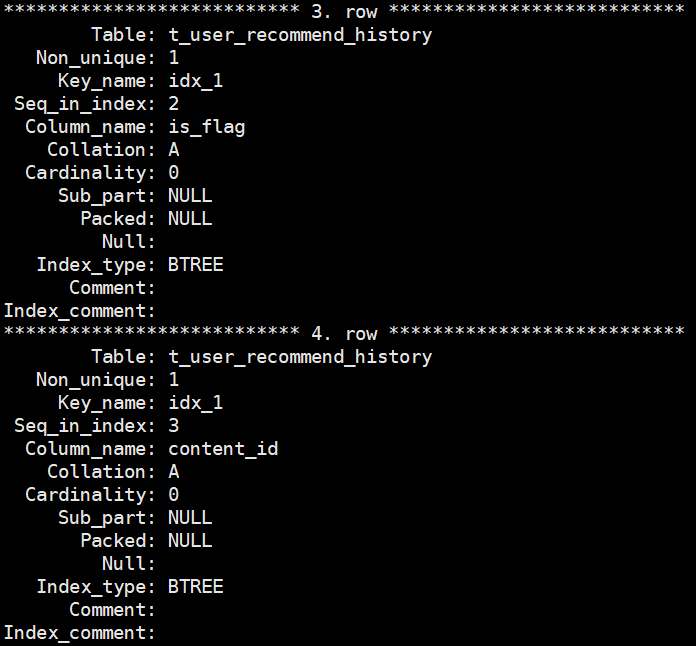
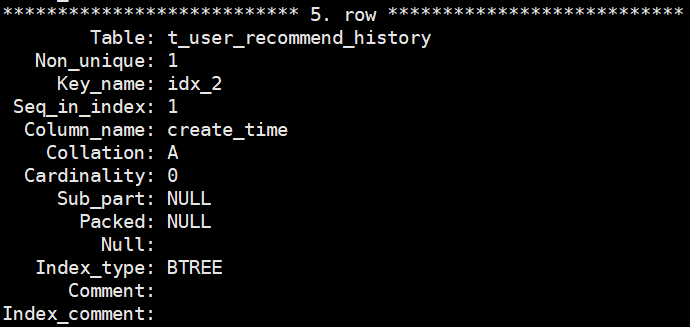
五、问题反思
- 大表DDL应使用pt-osc之类的工具,避免对原表影响;
- 对大表操作应谨慎和敬畏,执行超时应及时反馈和终止,且要随时观察;
Comments