
转自半同步复制
半同步复制
Ⅰ、认识半同步
我们目前MySQL默认的复制模式是异步复制,主不关心从的数据到哪里了,主宕了,做切换,如果从落后太多,就会导致丢失的数据太多
从5.5版本开始,MySQL引入了半同步复制
简单理解:一个事务提交时,日志至少要保证有一个从接收到,那么它的提交才能继续
到5.7版本,在原来半同步的基础上又出了一种半同步,叫无损复制,所以目前有两种半同步模式如下:
1.1 semi-sync replication
- 至少有一个从机收到binlog再返回
- 减少数据丢失风险
- 不能完全避免数据丢失
- MySQL5.5版本开始支持
1.2 lossless semi-sync replication
- 二进制日志先写远端
- 可保证数据完全不丢失
- MySQL5.7版本开始支持
Ⅱ、玩一手半同步
配置 semi-sync replication
step1:
在线加载插件安装
(root@localhost) [(none)]> install plugin rpl_semi_sync_master soname 'semisync_master.so';
(root@localhost) [(none)]> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
写入配置文件
[mysqld]
plugin-dir=/usr/local/mysql/lib/plugin
plugin-load="rpl_semi_sync_master:semisync_master.so;rpl_semi_sync_slave:semisync_slave.so"
(root@localhost) [(none)]> show plugins;
截取一段
+----------------------------+----------+--------------------+--------------------+---------+
| rpl_semi_sync_master | ACTIVE | REPLICATION | semisync_master.so | GPL |
| rpl_semi_sync_slave | ACTIVE | REPLICATION | semisync_slave.so | GPL |
+----------------------------+----------+--------------------+--------------------+---------+
可以看到已经装好了,还多了一些参数
(root@localhost) [(none)]> show variables like 'rpl%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32 |
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
9 rows in set (0.00 sec)
step2:
(root@localhost) [(none)]> set global rpl_semi_sync_master_enabled = 1;
(root@localhost) [(none)]> set global rpl_semi_sync_slave_enabled = 1;
tips:
配置文件里都配上哈,主从都搞好
重启一下复制
主上执行
(root@localhost) [(none)]> show global status like 'rpl%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 1 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
| Rpl_semi_sync_slave_status | OFF |
+--------------------------------------------+-------+
15 rows in set (0.03 sec)
这里面有一个超时,默认10s,如果超时了,会切为异步
相关参数:rpl_semi_sync_master_timeout
测试一把:
把从停掉(stop slave io_thread),主上insert,会被hang住 金融行业要超时时间设置很大,不让切异步,人工介入
主发给从,从没接收到,主提交不了
(root@localhost) [(none)]> show processlist;
+------+------+-----------+------+---------+------+--------------------------------------+---------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------+------+-----------+------+---------+------+--------------------------------------+---------------------------------------+
| 1460 | root | localhost | NULL | Query | 0 | starting | show processlist |
| 1461 | root | localhost | test | Query | 7 | Waiting for semi-sync ACK from slave | insert into flashback values(6,7,8,9) |
+------+------+-----------+------+---------+------+--------------------------------------+---------------------------------------+
跑sysbench批量插入,show processlist可以看到全是query end,卡住了,搞不进去,一会儿又恢复了
原因:10s后,半同步切换为异步了
此时主上看几个状态(截取几个重要的)
(root@localhost) [(none)]> show global status like 'rpl%';
+--------------------------------------------+---------+
| Variable_name | Value |
+--------------------------------------------+---------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_no_times | 1 | # 半同步切异步的次数
| Rpl_semi_sync_master_no_tx | 6588 | # 切为异步后执行的事务数
| Rpl_semi_sync_master_status | OFF |
+--------------------------------------------+---------+
15 rows in set (0.00 sec)
从:
(root@localhost) [(none)]> start slave io_thread;
Query OK, 0 rows affected (0.00 sec)
主:
恢复半同步,状态正常
半同步小结:
- 确保至少一个slave接收到日志
- 一段时间内没接收到就切到异步
- slave追上后又会自动切回半同步
Ⅲ、半同步原理浅析(两种模式)
3.1 semi-sync replication
半同步复制,一个事务提交(commit)时,在InnoDB层的commit log步骤后,Master节点需要收到至少一个Slave节点回复的ACK(表示收到了binlog )后,方可继续下一个事务
若在一定时间内(timeout)内没有收到ACK,则切换为异步模式,具体流程如下: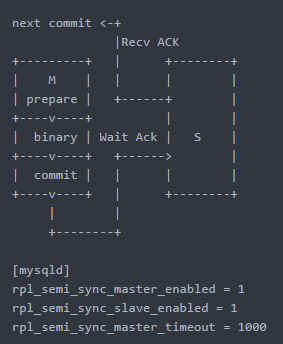
测试:
step1:
5.7默认是无损复制,先设一把普通半同步
主:
set global rpl_semi_sync_master_wait_point='after_commit';
step2:
主:
set global rpl_semi_sync_master_timeout = 3600; 不让切异步
create table a (a int primary key);
从:
stop slave io_thread;
step3:
主:
insert into a values(1);hang住咯
新开个线程,但可以看到这条记录
3.2 loss less semi-sync replication
无损复制,一个事务提交(commit)时,在server层的write binlog步骤后,Master节点需要收到至少一个Slave节点回复的ACK(表示收到了binlog )后,才能继续下一个事务
如果在一定时间内(timeout)内没有收到ACK ,则切换为异步模式 ,具体流程如下:
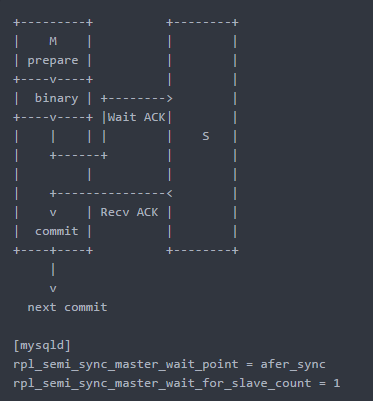
对比after_commit测试
同样的测试,被hang住的那条插入,在主上是不可见的
tips:
主从还未切换,主恢复的话,在两种复制模式下,主从的数据都是最终一致的(配置是crash_safe的)
3.3 小结对比
半同步模式| 等待ack时间点 |数据一致性
--|--|--
after_commit | commit后 | 无法保证主从一致
after_sync | 写binlog后 | 主从一致
```aaa
**tips:**
5.7新参数
rpl_semi_sync_master_wait_for_slave_count
之前的半同步是保证至少一个slave接收到binlog即可,这个参数可以设置多少个slave接收到日志主上才能commit
配置多个ACK和配置一个ACK的效果是类似的,因为他们是并行执行的(理论上来说不会有两倍的等待时间),取决于最慢的那个
建议设置从机数量的一半,类似group replication
但gr并没有走mysqldump去发送日志,它有专门的端口号,专门的paxos做日志发送,logshipping
## Ⅳ、几种复制的性能对比
### 4.1 先吹两手
异步复制和半同步复制(无损)的性能差多少?
- 只读的情况下,性能一样,因为没有产生二进制日志,谈不上主从
- oltp脚本(14个select,4个update)跑,性能其实也差不多
- update_none_index测试,差的也不多,百分之十的样子
综上:无损的半同步性能并不会下降非常多,性能下降多少和网络有关,用InfiniBand那更厉害了,另一点影响因素是事务的写入量,所以oltp差距不大
姜总测试报告:
两台不同机器,网络千兆,oltp,64个线程,异步和半同步差距可以忽略,百分之3到百分之5之间,纯update最差的时候差百分之三十
慢20%,主从严格一致,能接受不?
开更多线程呢?1024个线程去压呢?
半同步的性能会继续往上升,单个事务响应速度慢了,系统的整体吞吐率是上升的,所以生产环境中开启半同步,5.7场景打开after_sync(保证数据可靠性和性能的折中)
所以,5.7不用gr就能保证主从数据一致性,只是gr在做选主的话变成全自动了,不用mha,但它现在也还有一些明显的限制
### 4.2 再吹一手
从facebook测试结果看,after_commit性能很差,而无损复制比异步性能还好,为什么呢?
- 就等待ACK回包问题上,其实两种复制的开销是一样的,没有区别,都是网络的等待开销
- after_commit,主上一个事务等待提交的时候,不影响其他事务提交,性能一般
- after_sync,一个事务卡住(waiting for semi-sync ack),后面事务都是query end状态(执行中,没在等ack,binlog已经传到从上了,等待第一个事务被唤醒,后面的所有事务一起做最后一次fsync),变相提高了第三步(innodb commit)组提交的效率,减少上下文切换,降低io开销,降低资源之间的竞争,提升磁盘吞吐率,性能较好
- 线程数越多这种性能差距越明显
对比测试如下:
after_commit (root@localhost) [(none)]> show processlist; +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+ | Id | User | Host | db | Command | Time | State | Info | +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+ | 14905 | root | localhost | test | Query | 14 | Waiting for semi-sync ACK from slave | insert into abc values(1) | | 14906 | root | localhost | test | Query | 10 | Waiting for semi-sync ACK from slave | insert into abc values(2) | | 14907 | root | localhost | test | Query | 7 | Waiting for semi-sync ACK from slave | insert into abc values(3) | | 14908 | root | localhost | test | Query | 4 | Waiting for semi-sync ACK from slave | insert into abc values(4 | | 14909 | root | localhost | NULL | Query | 0 | starting | show processlist | +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+ 5 rows in set (0.00 sec)
after_sync (root@localhost) [(none)]> show processlist; +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+ | Id | User | Host | db | Command | Time | State | Info | +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+ | 14905 | root | localhost | test | Query | 57 | Waiting for semi-sync ACK from slave | insert into abc values(1) | | 14906 | root | localhost | test | Query | 37 | query end | insert into abc values(2) | | 14907 | root | localhost | test | Query | 29 | query end | insert into abc values(3) | | 14908 | root | localhost | test | Query | 21 | query end | insert into abc values(4) | | 14909 | root | localhost | NULL | Query | 0 | starting | show processlist | +-------+------+-----------+------+---------+------+--------------------------------------+---------------------------+
``` tips:
①为什么after_sync会堆积事务? 这种情况下主接受ack是在一个串行锁(LOCK_COMMIT)的保护下进行的,通过pstack抓线程栈可以看得很清楚,这一点after_commit没有
②ping值返回0.1ms是个什么水准? 千兆网的速度,万兆网0.01ms的样子
③开启半同步复制,sync_binlog可以不设为1来提升性能
错,除非是无损复制(日志先传到slave,sync_binlog可以不用持久化,那after_commit呢)
如果master宕机了,sync_binlog日志没落盘,redo里面有日志,这时候重启就会回滚事务,
回滚后,那slave上又有这个事务,这样就主从不一致了
这种说法,每次主起来的时候需要把从上面的binlog补过来,这个很复杂,很少有人可以做,很难
④线上环境可以配置成两台Slave做无损复制(保证数据不丢),其他的Slave做异步复制(配置为只读,用于负载均衡),都指向同一台Master
Comments